










Podcast: Play in new window | Download
Subscribe: Apple Podcasts | Spotify | TuneIn | RSS
We crack open our favorite book again, Designing Data-Intensive Applications by Martin Kleppmann, while Joe sounds different, Michael comes to a sad realization, and Allen also engages “no take backs”.
The full show notes for this episode are available at https://www.codingblocks.net/episode171.
Sponsors
- Datadog – Sign up today for a free 14 day trial and get a free Datadog t-shirt after creating your first dashboard.
- Linode – Sign up for $100 in free credit and simplify your infrastructure with Linode’s Linux virtual machines.
Survey Says
News
- Thank you for the review!
- iTunes: Wohim321

The Whys and Hows of Partitioning Data
- Partitioning is known by different names in different databases:
- Shard in MongoDB, ElasticSearch, SolrCloud,
- Region in HBase,
- Tablet in BigTable,
- vNode in Cassandra and Riak,
- vBucket in CouchBase.
- What are they?
- In contrast to the replication we discussed, partitioning is spreading the data out over multiple storage sections either because all the data won’t fit on a single storage mechanism or because you need faster read capabilities.
- Typically data records are stored on exactly one partition (record, row, document).
- Each partition is a mini database of its own.
Why partition? Scalability
- Different partitions can be put on completely separate nodes.
- This means that large data sets can be spread across many disks, and queries can be distributed across many processors.
- Each node executes queries for its own partition.
- For more processing power, spread the data across more nodes.
- Examples of these are NoSQL databases and Hadoop data warehouses.
- These can be set up for either analytic or transactional workloads.
- While partitioning means that records belong to a single partition, those partitions can still be replicated to other nodes for fault tolerance.
- A single node may store more than one partition.
- Nodes can also be a leader for some partitions and a follower for others.
- They noted that the partitioning scheme is mostly independent of the replication used.
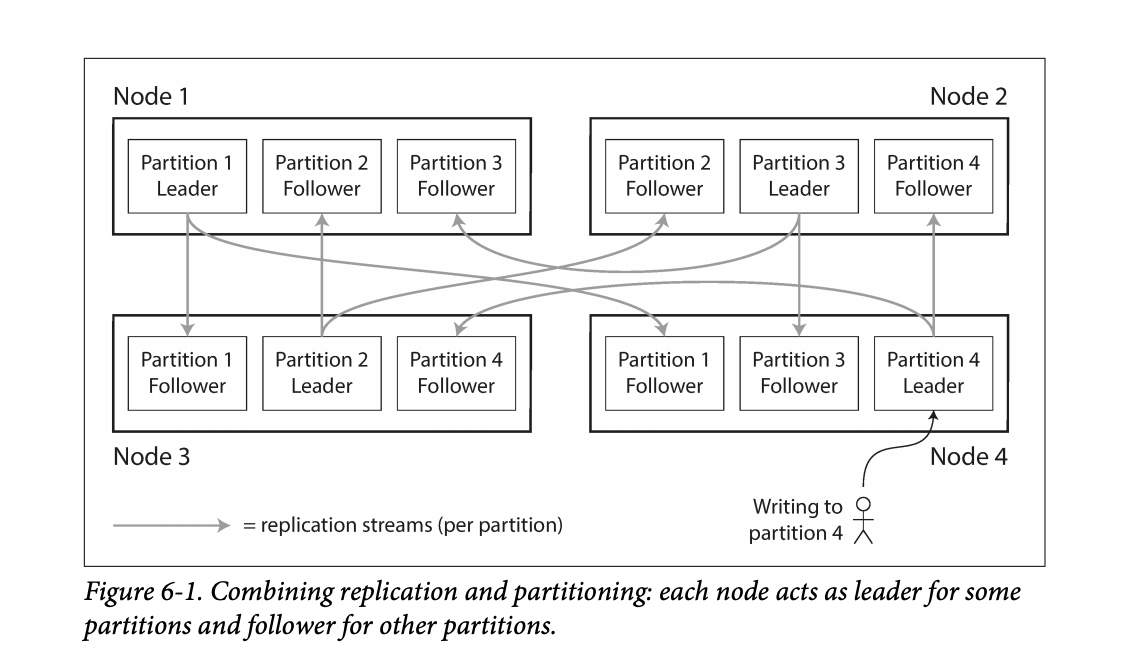
- The goal in partitioning is to try and spread the data around as evenly as possible.
- If data is unevenly spread, it is called skewed.
- Skewed partitioning is less effective as some nodes work harder while others are sitting more idle.
- Partitions with higher than normal loads are called hot spots.
- One way to avoid hot-spotting is putting data on random nodes.
- Problem with this is you won’t know where the data lives when running queries, so you have to query every node, which is not good.
Partitioning by Key Range
- Assign a continuous range of keys on a particular partition.
- Just like old encyclopedias or even the rows of shelves in a library.
- By doing this type of partitioning, your database can know which node to query for a specific key.
- Partition boundaries can be determined manually or they can be determined by the database system.
- Automatic partition is done by BigTable, HBase, RethinkDB, and MongoDB.
- The partitions can keep the keys sorted which allow for fast lookups. Think back to the SSTables and LSM Trees.
- They used the example of using timestamps as the key for sensor data – ie
YY-MM-DD-HH-MM. - The problem with this is this can lead to hot-spotting on writes. All other nodes are sitting around doing nothing while the node with today’s partition is busy.
- One way they mentioned you could avoid this hot-spotting is maybe you prefix the timestamp with the name of the sensor, which could balance writing to different nodes.
- The downside to this is now if you wanted the data for all the sensors you’d have to issue separate range queries for each sensor to get that time range of data.
- Some databases attempt to mitigate the downsides of hot-spotting. For example, Elastic has the ability specify an index lifecycle that can move data around based on the key. Take the sensor example for instance, new data comes in but the data is rarely old. Depending on the query patterns it may make sense to move older data to slower machines to save money as time marches on. Elastic uses a temperature analogy allowing you to specify policies for data that is hot, warm, cold, or frozen.
Partitioning by Hash of the Key
- To avoid the skew and hot-spot issues, many data stores use the key hashing for distributing the data.
- A good hashing function will take data and make it evenly distributed.
- Hashing algorithms for the sake of distribution do not need to be cryptographically strong.
- Mongo uses MD5.
- Cassandra uses Murmur3.
- Voldemort uses Fowler-Noll-Vo.
- Another interesting thing is not all programming languages have suitable hashing algorithms. Why? Because the hash will change for the same key. Java’s
object.hashCode()and Ruby’sObject#hashwere called out. - Partition boundaries can be set evenly or done pseudo-randomly, aka consistent hashing.
- Consistent hashing doesn’t work well for databases.
- While the hashing of keys buys you good distribution, you lose the ability to do range queries on known nodes, so now those range queries are run against all nodes.
- Some databases don’t even allow range queries on the primary keys, such as Riak, Couchbase, and Voldemort.
- Cassandra actually does a combination of keying strategies.
- They use the first column of a compound key for hashing.
- The other columns in the compound key are used for sorting the data.
- This means you can’t do a range query over the first portion of a key, but if you specify a fixed key for the first column you can do a range query over the other columns in the compound key.
- An example usage would be storing all posts on social media by the user id as the hashing column and the updated date as the additional column in the compound key, then you can quickly retrieve all posts by the user using a single partition.
- Hashing is used to help prevent hot-spots but there are situations where they can still occur.
- Popular social media personality with millions of followers may cause unusual activity on a partition.
- Most systems cannot automatically handle that type of skew.
- In the case that something like this happens, it’s up to the application to try and “fix” the skew. One example provided in the book included appending a random 2 digit number to the key would spread that record out over 100 partitions.
- Again, this is great for spreading out the writes, but now your reads will have to issue queries to 100 different partitions.
- Couple examples:
- Sensor data: as new readings come in, users can view real-time data and pull reports of historical data,
- Multi-tenant / SAAS platforms,
- Giant e-commerce product catalog,
- Social media platform users, such as Twitter and Facebook.

Resources We Like
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann (Amazon)
- History of Google (Wikipedia)
Tip of the Week
- VS Code lets you open the search results in an editor instead of the side bar, making it easier to share your results or further refine them with something like regular expressions.
- Apple Magic Keyboard (for iPad Pro 12.9-inch – 5th Generation) is on sale on Amazon. Normally $349, now $242.99 on Amazon and Best Buy usually matches Amazon.(Amazon)
- Compatible Devices:
- iPad Pro 12.9-inch (5th generation),
- iPad Pro 12.9-inch (4th generation),
- iPad Pro 12.9-inch (3rd generation)
- Compatible Devices:
- Room EQ Wizard is free software for room acoustic, loudspeaker, and audio device measurements. (RoomEQWizard.com)
